◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。
黑客在线接单先做事后付款,诚信黑客先做事后付款企鹅
爬虫在情报获取、虚假流量、动态定价、恶意攻击、薅羊毛等方面都能起到很关键的作用,所以每家公司都或多或少的需要开发一些爬虫程序,业界在这方面的成熟的方案也非常多。
有矛就有盾,每家公司也相应的需要反爬虫系统来达到数据保护、系统稳定性保障、竞争优势保持的目的。
像安全与黑客从来都是相辅相成一样。
爬虫与反爬虫也是在双方程序员的斗智斗勇的过程不断发展和成长的。
抓包
抓包的目的: 分析出协议请求使用的数据,请求接口,参数等等。
常用的抓包分析工具:
Fiddler
Charles
Sniffer
Wireshark
具体使用策略,请自行百度,Google。

抓数据
使用 HttpClient 模拟请求

充分了解 HttpClient 的特性,使用方式等。
HttpClient4.5官方教程
user_agent 的使用
使用 user_agent 的伪装和轮换模拟不同的客户端。
建立UserAgent池,可以通过以下地址获取一定量的UserAgent的信息。
1 |
http://www.fynas.com/ua/search?b=Chrome&k= |
代理IP的使用
建立代理ip池,一般使用的免费或收费代理获取代理ip每秒都会有一定的频率限制。
那么我们在使用的时候,就要在频率限制内建立自己内部的一些策略,
当然这些策略建立在代理服务商的策略之上。因此设计实施时要考虑易维护性。
http代理
有些网站(包括APP、PC)具有一定的反爬虫能力,
如拒绝代理ip直接请求接口:
这是我使用代理ip请求登录接口时,某APP的响应:

1 |
CONNECT refused by proxy |
而使用socks代理则无此问题。这就不得不要了解http代理和socks代理的区别。
socks代理
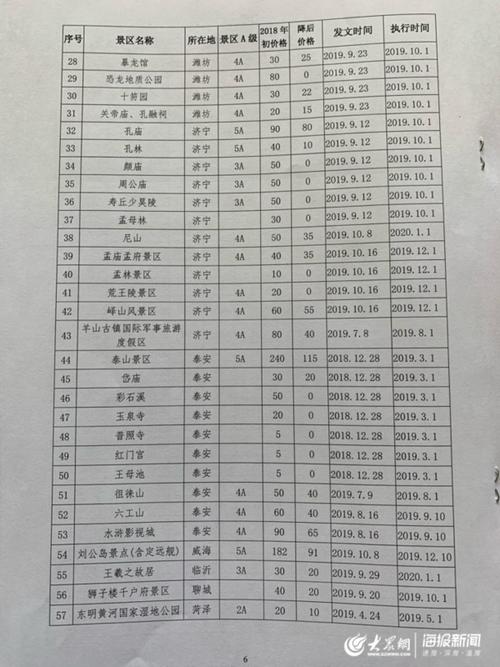
待续
设置访问频率
即便是使用了代理ip,那么对目标接口的访问也要有一定的频率控制,
防止目标服务方检测出频率过快,进行拒绝服务的响应。
Cookie 池失效和更新策略

获取目标站点Cookie有效时间,
将对应账号和Cookie存入Redis,
起一个任务对账号Cookie进行定时检测,
接近失效时间,进行提前更新Cookie信息,
具体Cookie 池Cookie的失效和更新策略需要根据自己业务进行适当调整。
防止目标方的分析

- 确保同一账号的请求使用的是同一个UserAgent、同一个代理ip。
注意访问频率
其他
总而言之,就是模拟正常的客户端发起对服务方的请求,伪装的越像正常的客户端,服务方越难分析出。
只要是服务方能够提供服务,一般情况下都可以进行数据的爬取,
延伸阅读
- 搜索
- 最新留言
-
- ▇▇▇▇看 黃 片 8aaab.COM ▇▇▇▇▇▇▇▇
- ▇▇▇▇看 黃 片 8aaab.COM ▇▇▇▇▇▇▇▇▇▇▇▇看 黃 片 8aaab.COM ▇▇▇▇▇▇▇▇
- ▇▇▇▇看 黃 片 8aaab.COM ▇▇▇▇▇▇▇▇▇▇▇▇看 黃 片 8aaab.COM ▇▇▇▇▇▇▇▇▇▇▇▇看 黃 片 8aaab.COM ▇▇▇▇▇▇▇▇
- ▇▇▇▇看 黃 片 8aaab.COM ▇▇▇▇▇▇▇▇▇▇▇▇看 黃 片 8aaab.COM ▇▇▇▇▇▇▇▇
- ▇▇▇▇看 黃 片 8aaab.COM ▇▇▇▇▇▇▇▇
- ▇▇▇▇是那种男人晚上爱看的 8 a a a b。 C 0 M ▇▇▇▇
- ▇▇▇▇是那种男人晚上爱看的 8 a a a b。 C 0 M ▇▇▇▇▇▇▇▇是那种男人晚上爱看的 8 a a a b。 C 0 M ▇▇▇▇
- ▇▇▇▇是那种男人晚上爱看的 8 a a a b。 C 0 M ▇▇▇▇▇▇▇▇是那种男人晚上爱看的 8 a a a b。 C 0 M ▇▇▇▇▇▇▇▇是那种男人晚上爱看的 8 a a a b。 C 0 M ▇▇▇▇
- ▇▇▇▇▇▇两夫妻在家光 着大度尺 8aaab.COM ▇▇▇▇▇▇▇▇▇▇▇▇两夫妻在家光 着大度尺 8aaab.COM ▇▇▇▇▇▇▇▇▇▇▇▇两夫妻在家光 着大度尺 8aaab.COM ▇▇▇▇▇▇
- ▇▇▇▇▇▇两夫妻在家光 着大度尺 8aaab.COM ▇▇▇▇▇▇▇▇▇▇▇▇两夫妻在家光 着大度尺 8aaab.COM ▇▇▇▇▇▇
- 标签列表
-